Abstract
We introduce a new benchmark designed to advance the development of general-purpose, large-scale vision-language models for remote sensing images. Although several vision-language datasets in remote sensing have been proposed to pursue this goal, existing datasets are typically tailored to single tasks, lack detailed object information, or suffer from inadequate quality control. Exploring these improvement opportunities, we present a Versatile vision-language Benchmark for Remote Sensing image understanding, termed VRSBench. This benchmark comprises 29,614 images, with 29,614 human-verified detailed captions, 52,472 object references, and 123,221 question-answer pairs. It facilitates the training and evaluation of vision-language models across a broad spectrum of remote sensing image understanding tasks. We further evaluated state-of-the-art models on this benchmark for three vision-language tasks: image captioning, visual grounding, and visual question answering. Our work aims to significantly contribute to the development of advanced vision-language models in the field of remote sensing. The data and code can be accessed at https://github.com/lx709/VRSBench.
VRSBench Dataset
-
VRSBench provides large-scale human-verified annotations that feature several advantages:
- VRSBench provides a large-scale collection of human-verified, high-quality captions rich in object details.
- VRSBench offers more realistic object refers in which each referring sentence unambiguously identifies an object among multiple similar ones within the same category.
- VRSBench features a diverse collection of open-set question-answer pairs in natural language.
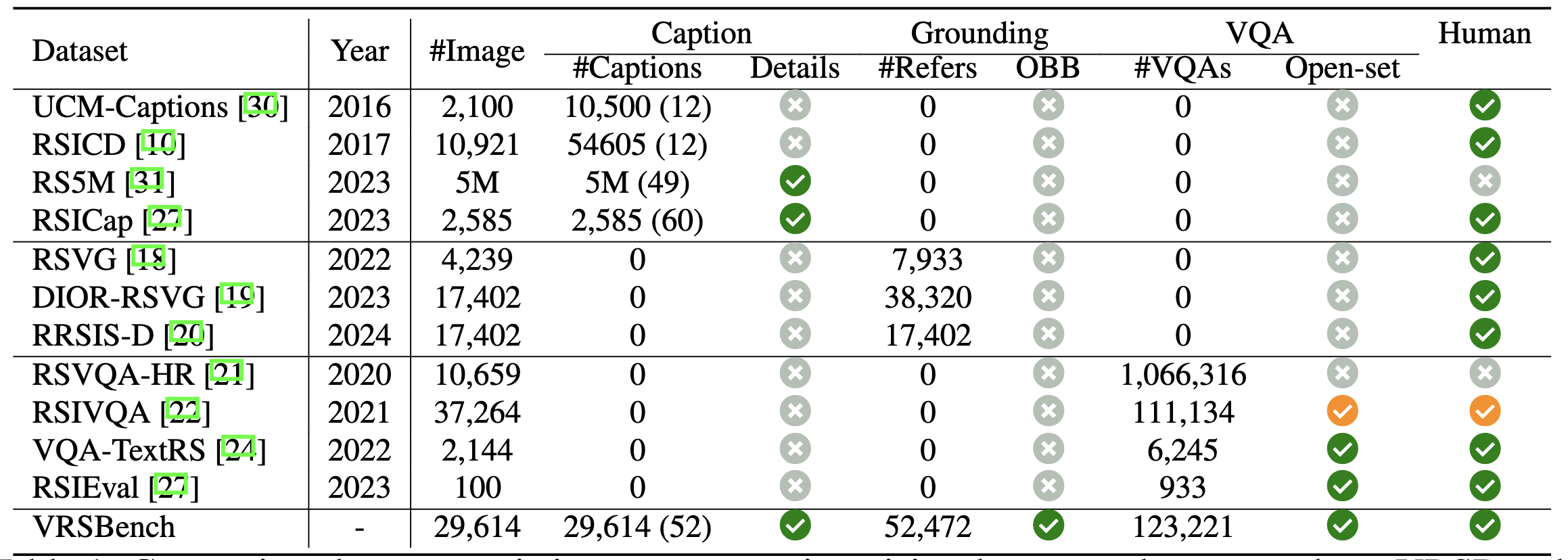
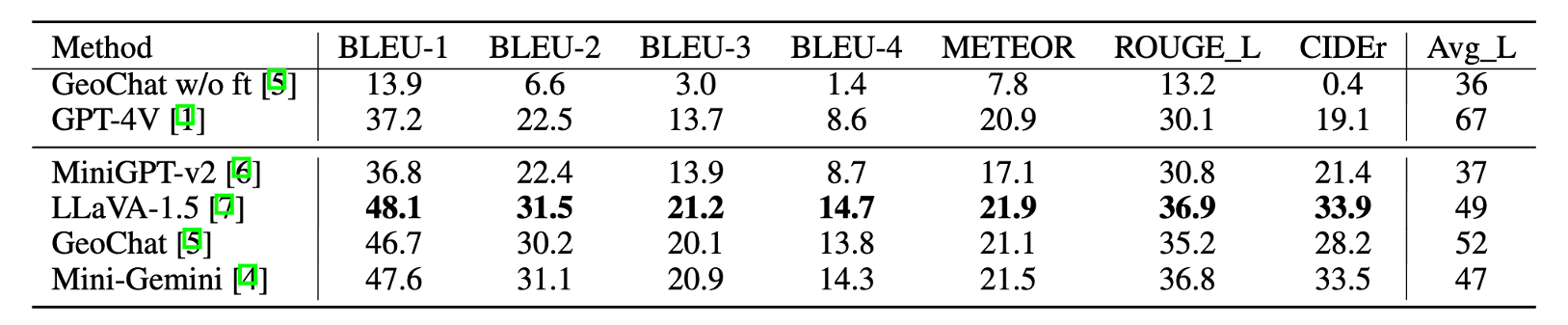
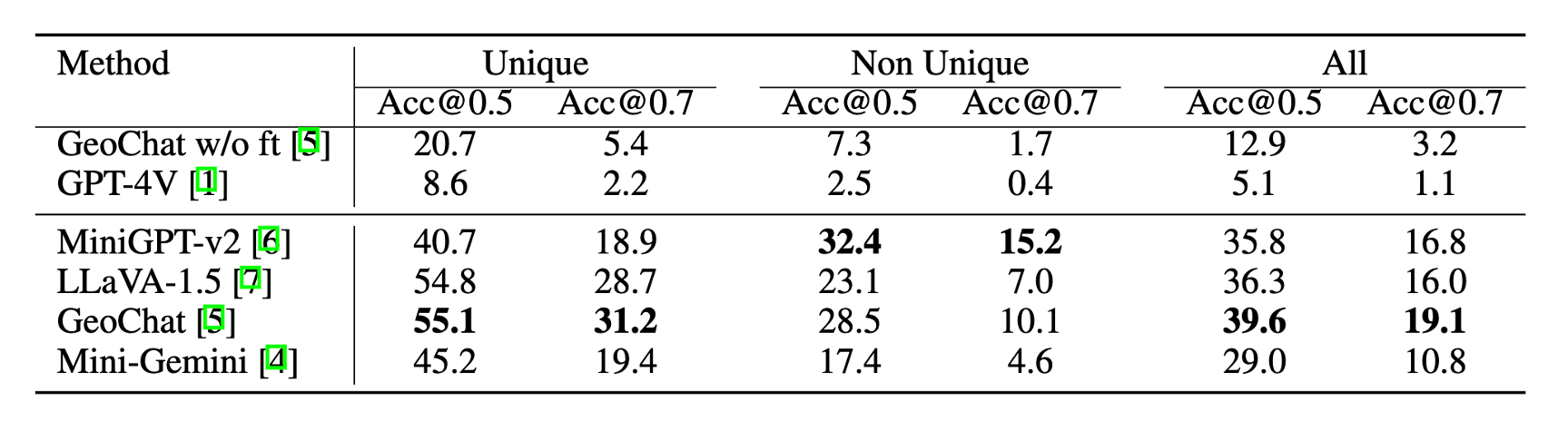
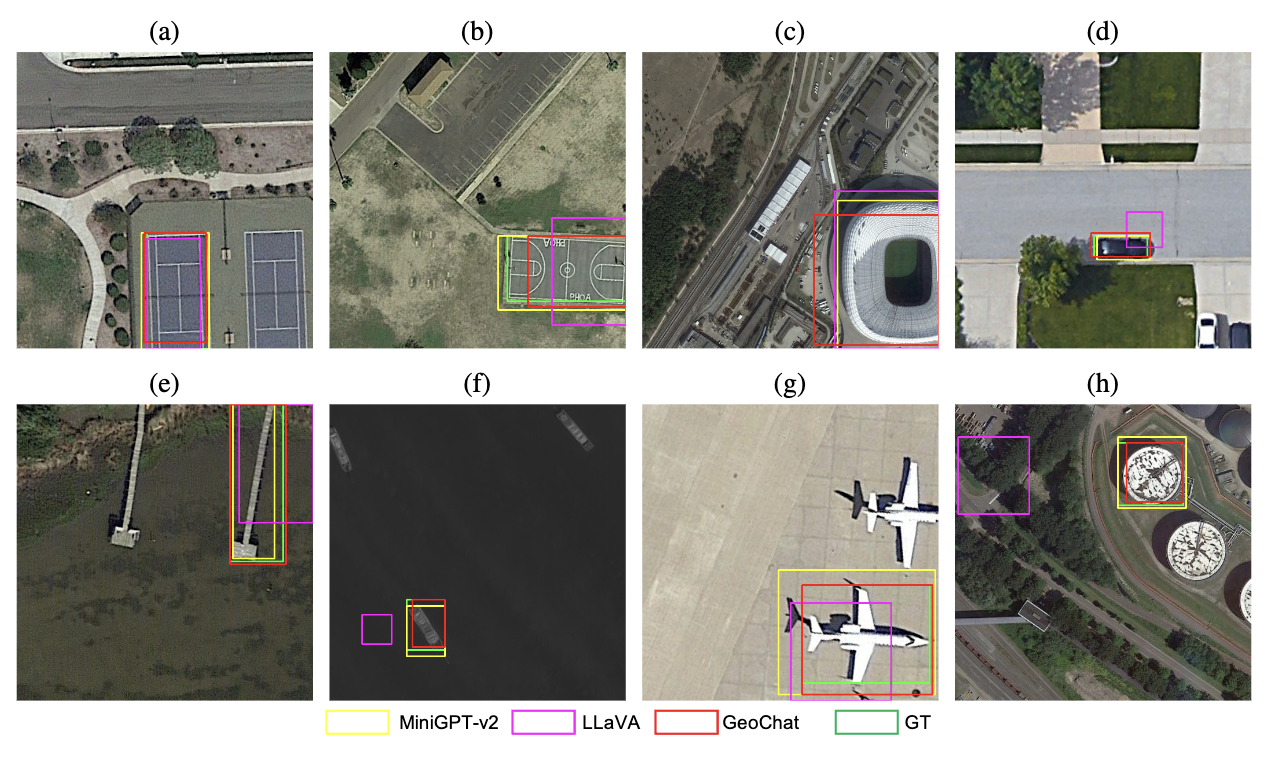
Table 1. Comparison between existing remote sensing vision-language datasets and our VRSBench dataset. Values in parentheses in the Caption column indicate the average word length of captions. OBB denotes orientated bounding box. A small portion of question-answer pairs in RSIVQA areannotated by human annotators.
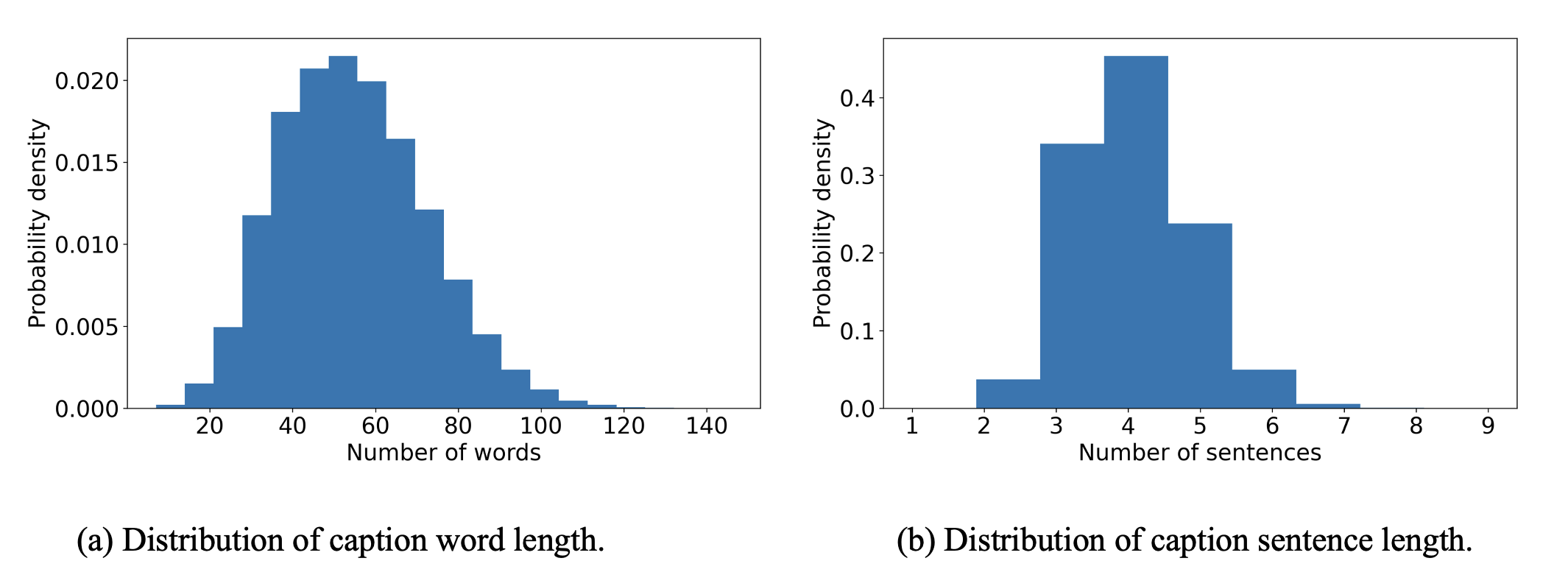
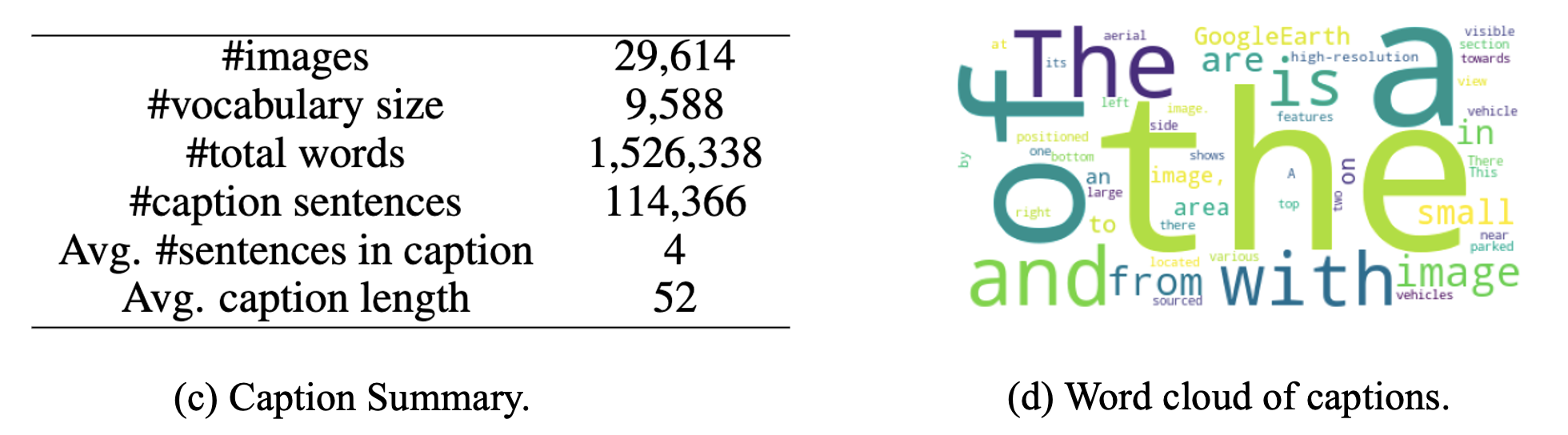
Figure 2. Statistics of the VRSBench caption dataset. (a) Probability density function (PDF) of caption length. (b) PDF of the sentence number. (c) Summative statistics. (d) Word cloud of top-50 words.
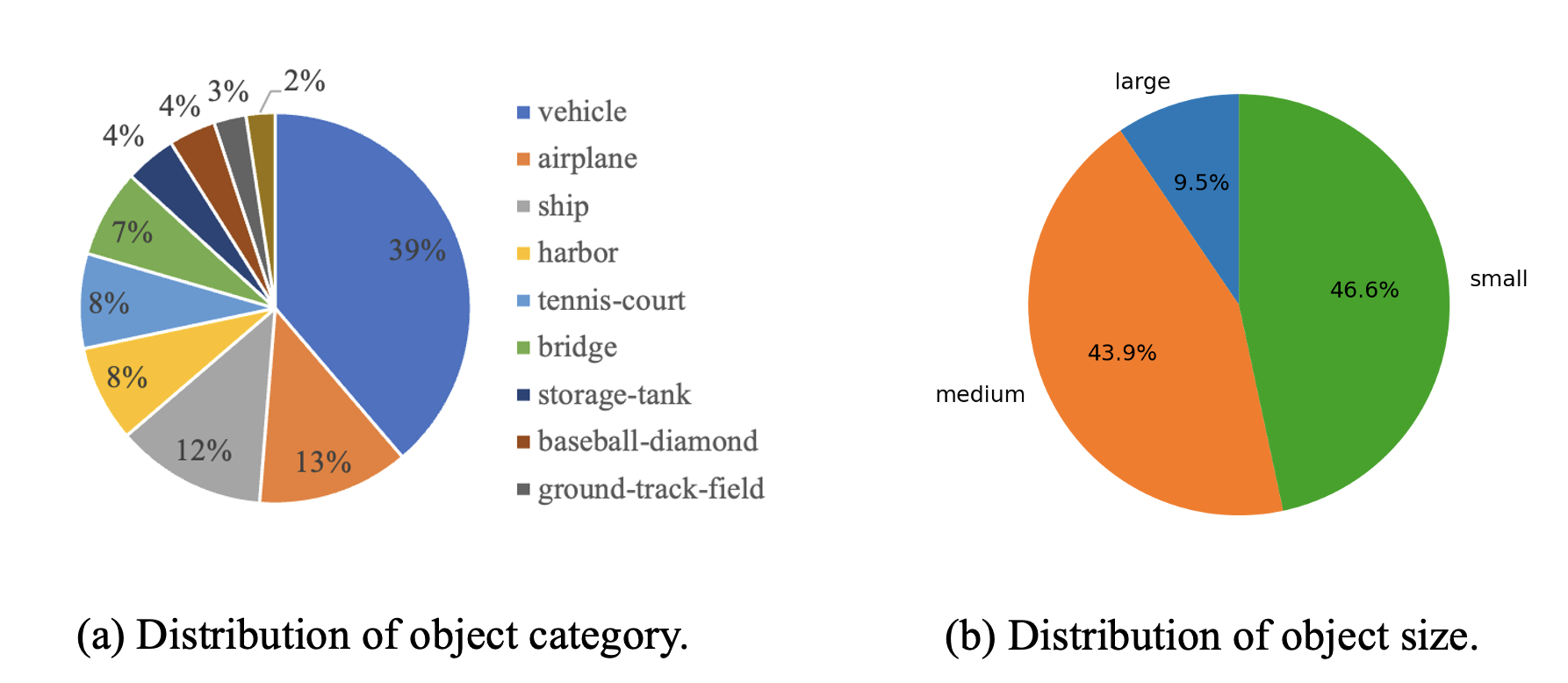
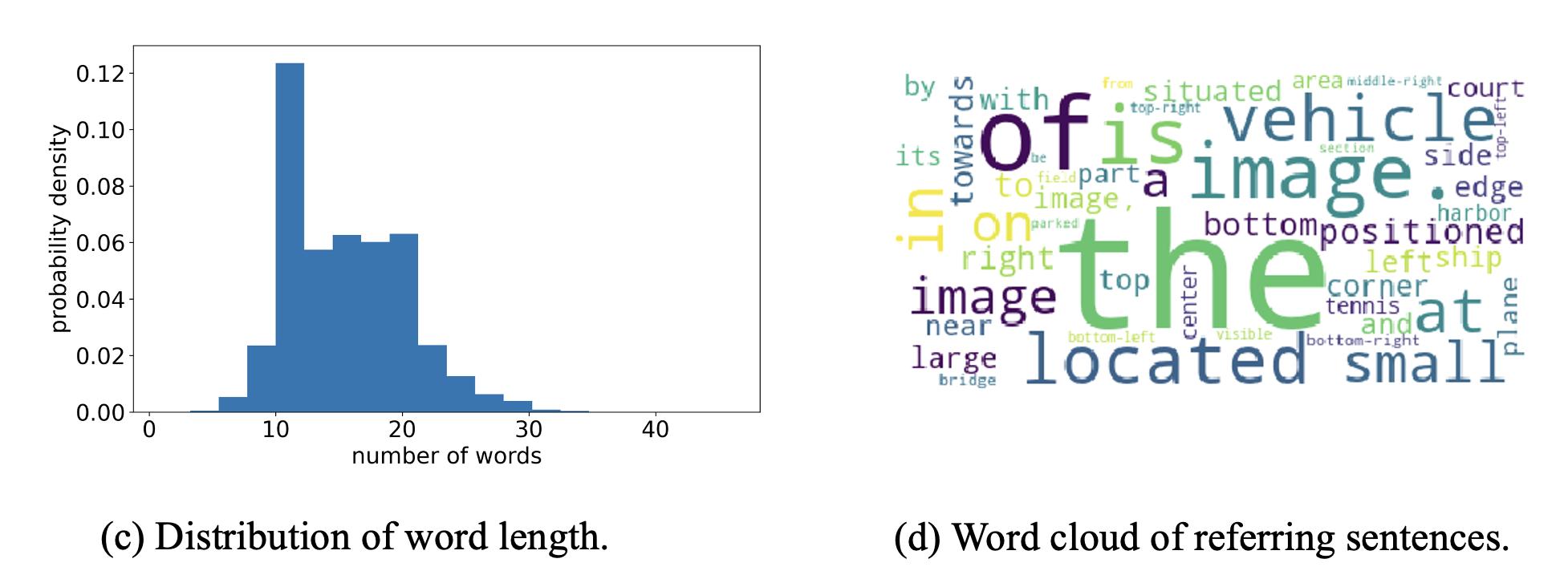
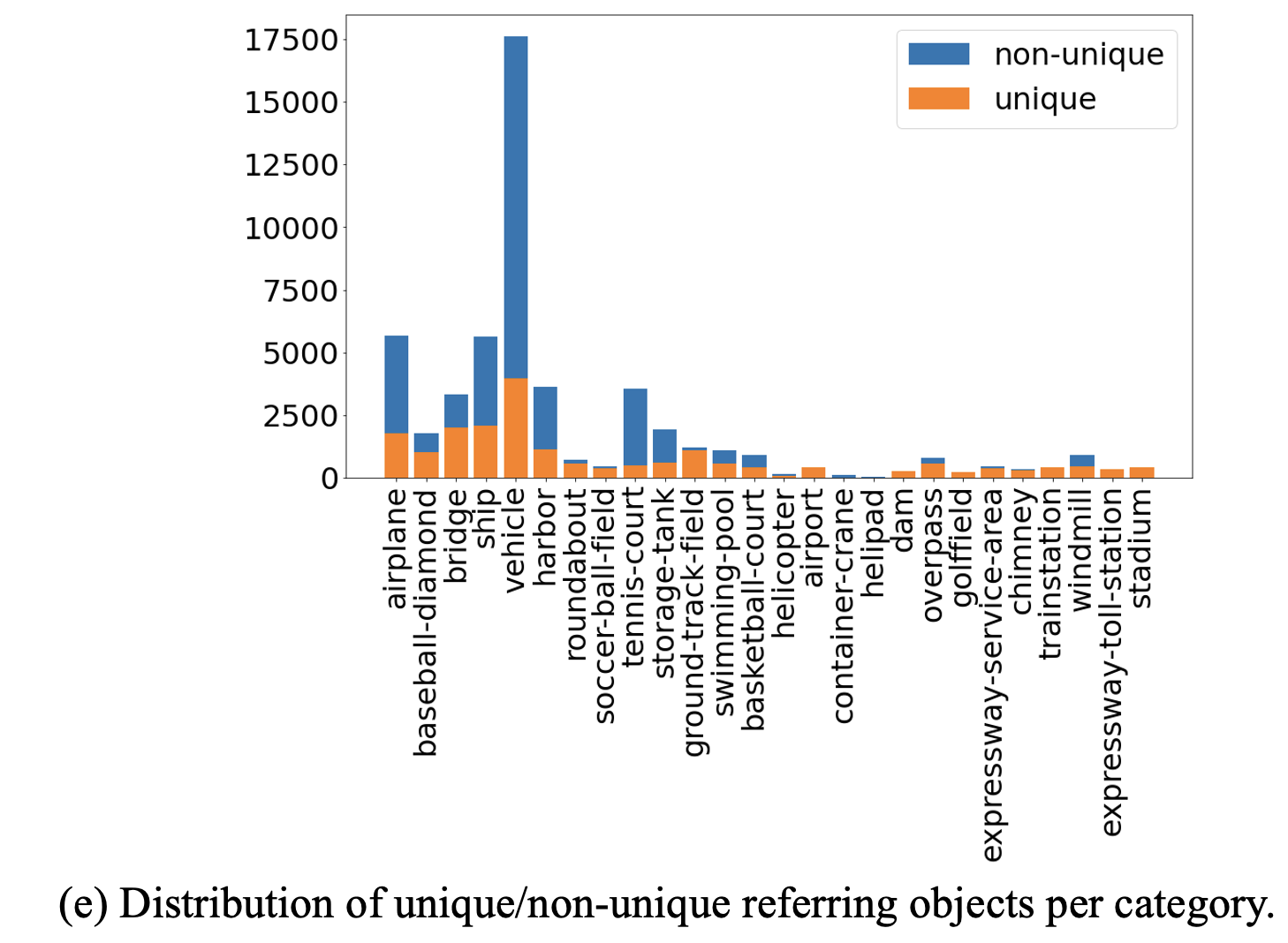
Figure 3. Statistics of object referring sentences of VRSBench dataset. (a) Distribution of the 10 most frequent object categories. (b) Distribution of the word length of referring sentences. (c) Distribution of object size. (d)Word cloud of the top 50 words in referring sentences. (e) Distribution of unique/non-unique objects in each category.
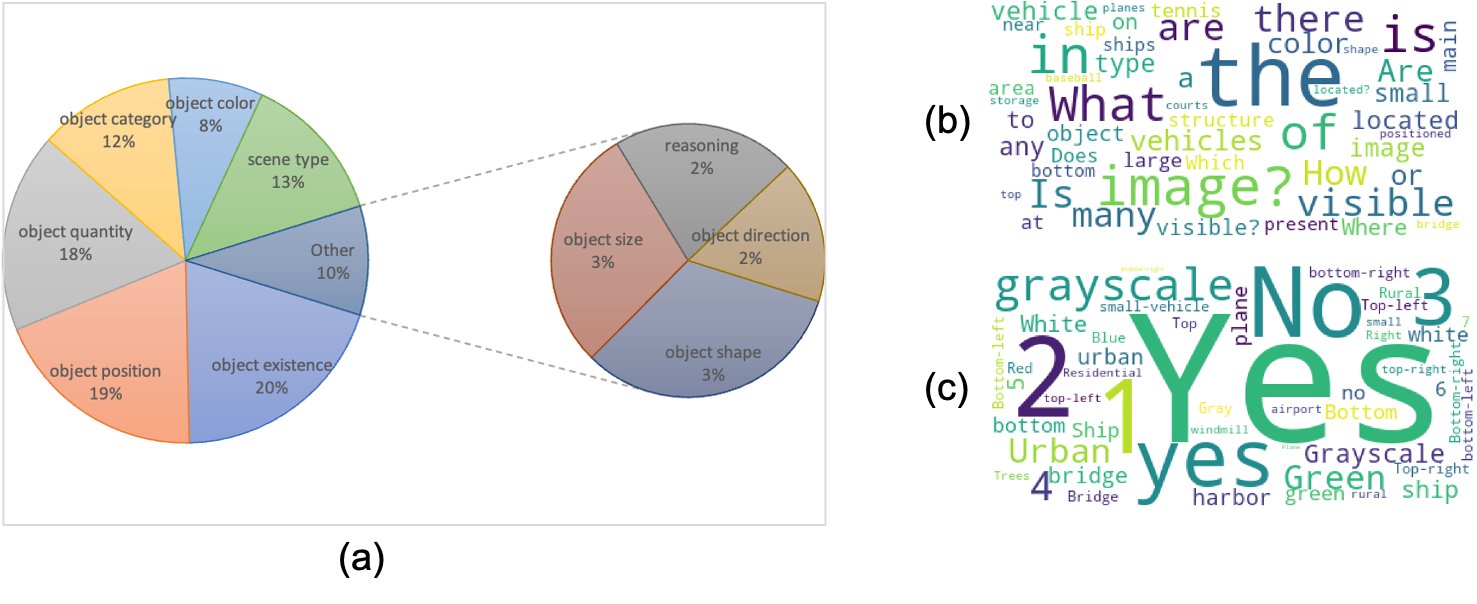
Figure 3. Statistics of object referring sentences of VRSBench dataset. (a) Distribution of question types. (b) Word cloud of top 50 most frequent words in questions. (c) Word cloud of top 50 most frequent words in answers.